Experiments and Findings
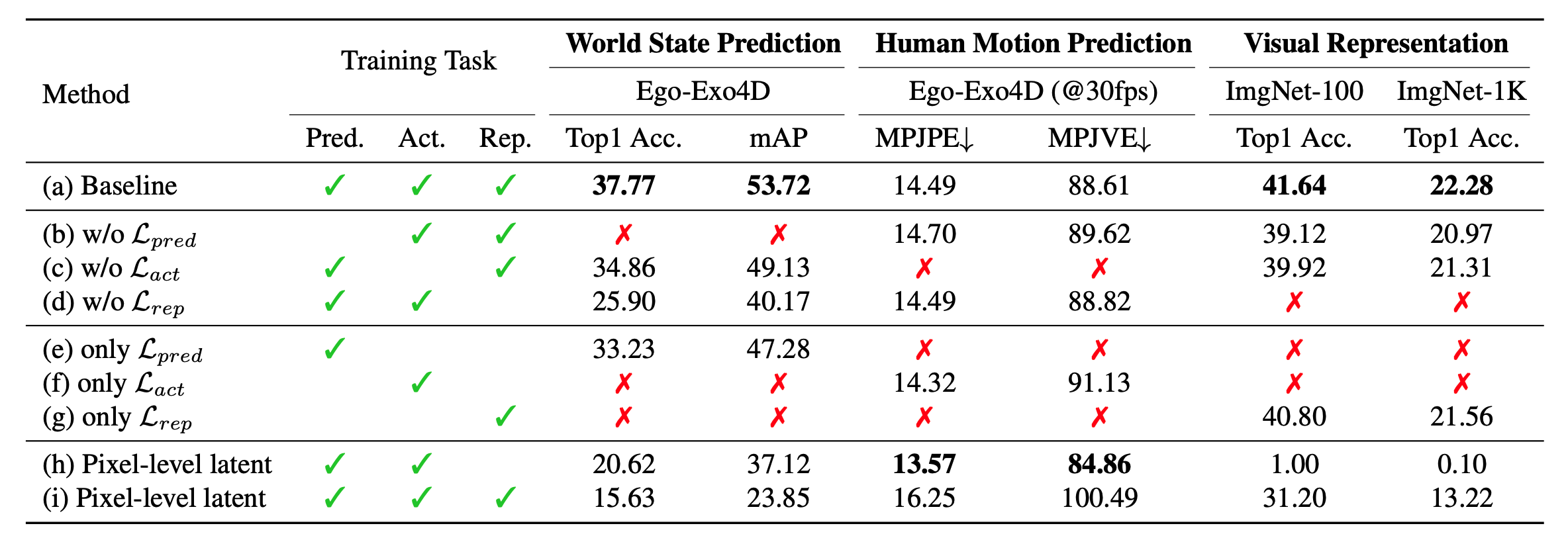
Synergy between the Three Learning Tasks
We demonstrate that removing any one of the three tasks (prediction, action, and representation) during training (lines b–d), or training on a single task alone (lines e–g), reduces baseline performance. Additionally, we find that learning in a high-level semantic feature space reduces the overall difficulty of the learning process compared to learning in a pixel-level latent space from a pretrained VQGAN (lines h-i).
Feature Map and 3D Action Prediction Visualization
EgoAgent can extract semantic features from first-person RGB images and predicts the next 3D human action, as if anticipating what a human would do next based on what they have seen.
World Model Predictions in Learned Semantic Space
EgoAgent also predicts the global semantics of the next world state after the predicted action is taken. These predicted states can be interpreted and verified through image retrieval within the video.

Transfering to Egocentric Embodied Manipulation
We freeze the pretrained EgoAgent vision-action backbone and add a three-layer MLP as the policy network to train on the TriFinger benchmark. EgoAgent achieves the highest success rates compared to vision-only representation models, such as DINO and DoRA, trained on egocentric datasets.
Related Links
There are some excellent works that were introduced around the same time as ours.
HMA proposes a unified model that simultaneously learns to represent and generate action-conditioned video dynamics across diverse robotic domains and embodiments.
UVA introduces a joint video–action model that learns a shared latent representation to predict both video frames and corresponding actions efficiently.